Contract Analytics
The text in contracts is typically understood to be unstructured data, but contracts are in fact highly structured, like software code.
Last week, I had the chance to participate in a podcast hosted by Evan Schnidman and Omri Shtayer at I See Data People, a biopic interview series on people in data.
I really enjoyed the format, which encourages a deeper focus on cross-domain thinking. I believe such thinking is critical for innovation in conservative fields like law, where what has worked, has worked that way for a very long time. However, it’s not always about applying radically different ideas from other fields. Rather, it can be more about finding similarities (sometimes non-obvious) and applying what works in one domain to parallel structures in the other.
In the podcast, I skim the surface of a few thoughts about contracts as data, in particular whether contract data is structured, and the similarities between “software as code” and “contracts as code”. Now, let's take a deeper dive into this topic in this blog post.
Contract data: is it unstructured or structured data?
The text in contracts is typically understood to be unstructured data, which in a basic sense it clearly is—there is no fixed format or schema. Largely fruitless efforts of document standardization aside, the permutations and combinations of ways that lawyers will express something that really has no need to vary is astounding, as in the example below showing the various ways of expressing California Governing Law.
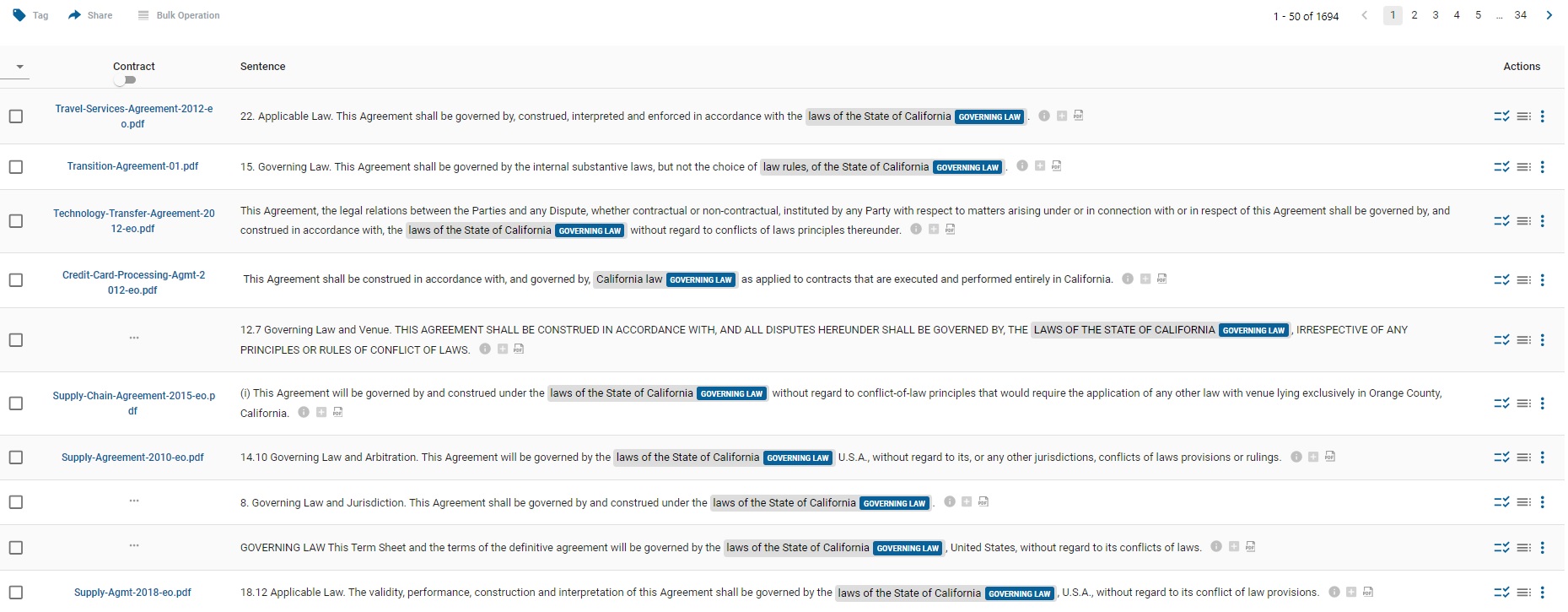
Of course substantive differences: exceptions, parameters and subtle meaning, can accompany superficial variation. For example, finding assignment restrictions, no matter how they are worded, is the first step toward understanding what matters in assignment restrictions:
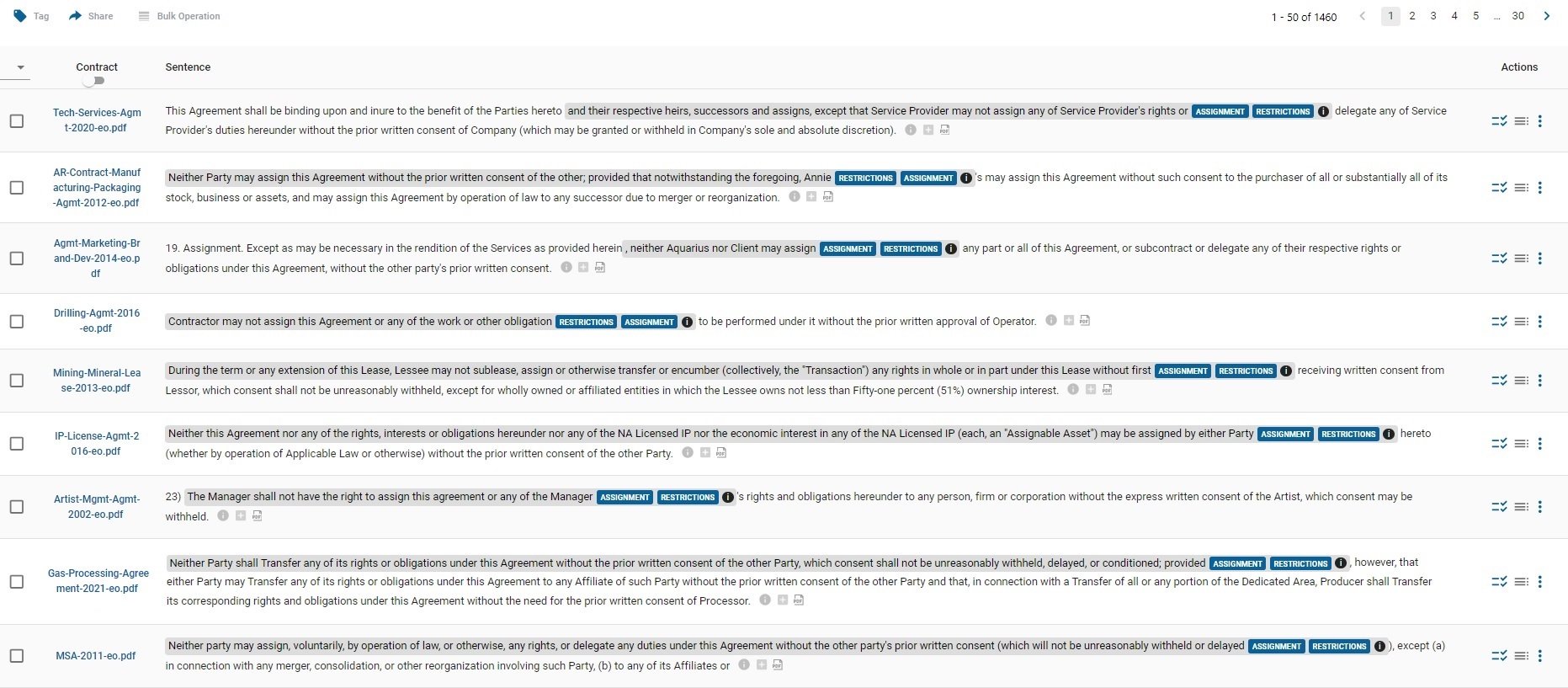
In essence, contracts are in fact highly structured, like software code in that they are methodically crafted, with specific syntax and established conventions. In most cases, lawyers attempt to structure language in a way that leaves little room for misinterpretation by judges or arbitrators (or, more frequently, opposing counsel in settlement negotiations).
Of course, lawyers sometimes fail in their efforts to draft unambiguous “code”, sometimes egregiously or even obviously so. This is where the difference between “contracts as code” and “software as code” diverges the most.
"Contacts as code" versus "software as code"
In software, simple bugs are often found before the code is even run, when the code is compiled. More complex bugs can be unearthed with methodical testing, both manually and with automation. The most complex bugs will persist post release, to confound users and re-engage developers in sometimes painful diagnosis.
In contrast, a simple “bug” in a contract may be caught by the drafting associate before he submits to his partner, or in the heavy mark-up she gives back, or perhaps by the client in a last read through prior to execution, or maybe even by conscientious counsel on the other side. It can also be missed (or intentionally ignored) by all of the above and make it into the final draft.
Complex “bugs” introduced by inapposite use of precedents and referenced terms more easily evade detection (and serve to build vacation houses for litigation partners, often working for completely different firms than those that draft). Deeply latent “bugs” where whole classes of contracts fail to work as intended may only come out when tested by cataclysm and crisis.
Contract analytics starts to bridge the gap, with the “structured” data in contracts transforming to the “structured” data in machines.